Content Builder Agent — multi-objective CSP and the fluent ConstraintBuilder#
A Tier 3 tutorial that translates the deepagents content builder pattern — a multi-format content marketing workflow driven by subagents — into LangGOAP. Where the deepagents version leans on a supervisor LLM and subagent routing, the GOAP version replaces the orchestration layer with A* → CSP planning while keeping real LLM intelligence inside every content-generating action. Research, outlining, blog writing, LinkedIn posts, and Twitter threads are all produced by actual LLM calls; only image generation and platform publishing remain stubs (a text LLM cannot produce images, and publishing requires platform API credentials).
Three features are on display at once:
Conditional format generation via CSP enumeration. Two competing blog writers (
write_blog_fast,write_blog_deep) share the same effectblog_drafted=Truebut have very different cost, writer-hour, and quality profiles. A* alone always picks the cheaper fast writer. When the goal adds a hardquality_score >= 8floor, the pipeline’senumerate_alternativespath kicks in, blacklists each action in the rejected plan, re-runs A*, and swaps in the deep writer. This is the cleanest in-tree demonstration of the enumeration branch inlanggoap/planner/pipeline.py.Multi-objective CSP with hard and soft levels. The premium campaign goal carries a hard
cost_usdcap (violation → INFEASIBLE), a softwriter_hourscap (violation → penalty inHardSoftScore), a MINIMIZE objective, and a MAXIMIZE objective. The notebook decomposes the resulting score into its exact contributions.Fluent
ConstraintBuilderas aConstraintProvideranalogue. Every goal has a hand-rolled form and a builder form; the integration test pins that they produce structurally identicalGoalSpecinstances.
The corresponding integration test is tests/integration/test_content_builder_agent.py. Every assertion in this notebook is mirrored there and runs on every CI build.
1. The content domain#
tutorial_examples.content_builder_agent exposes the factories this notebook uses:
content_builder_actions()— twelveActionSpecs spanning research, outline, three content formats (blog/LinkedIn/Twitter), image generation per format, and publishing.content_builder_start()— clean-slate world state with every milestone flagFalse.blog_only_goal(),multi_channel_goal(...),quality_blog_goal(...),quality_blog_goal_fluent(...),premium_campaign_goal(...),premium_campaign_goal_fluent(...)— progressively richer goals that showcase each CSP feature.
The action catalog is intentionally small so every plan’s resource totals can be computed by hand:
Environment Setup#
This notebook requires an OpenAI API key for the LLM-powered content-generating
actions (research_topic, draft_outline, blog/LinkedIn/Twitter writers).
Image generation and publishing actions remain stubs.
export OPENAI_API_KEY="sk-..."
from langchain_openai import ChatOpenAI
from tutorial_examples.content_builder_agent import (
blog_only_goal,
content_builder_actions,
content_builder_start,
multi_channel_goal,
premium_campaign_goal,
premium_campaign_goal_fluent,
quality_blog_goal,
quality_blog_goal_fluent,
)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
actions = content_builder_actions(llm)
print(f"catalog size : {len(actions)} actions\n")
for a in actions:
pre = dict(a.preconditions) or "(none)"
eff = dict(a.effects)
res = dict(a.resources) if a.resources else "(none)"
print(f"{a.name:<24s} pre={pre}")
print(f"{'':<24s} eff={eff}")
print(f"{'':<24s} cost={a.cost} resources={res}")
catalog size : 12 actions
research_topic pre=(none)
eff={'research_done': True}
cost=1.0 resources={'writer_hours': 1.0, 'cost_usd': 5.0}
draft_outline pre={'research_done': True}
eff={'outline_ready': True}
cost=1.0 resources={'writer_hours': 2.0, 'cost_usd': 10.0}
write_blog_fast pre={'outline_ready': True}
eff={'blog_drafted': True}
cost=3.0 resources={'writer_hours': 2.0, 'cost_usd': 30.0, 'quality_score': 5.0}
write_blog_deep pre={'outline_ready': True}
eff={'blog_drafted': True}
cost=6.0 resources={'writer_hours': 6.0, 'cost_usd': 80.0, 'quality_score': 10.0}
generate_blog_cover pre={'blog_drafted': True}
eff={'blog_cover_ready': True}
cost=2.0 resources={'gpu_minutes': 5.0, 'cost_usd': 15.0}
publish_blog pre={'blog_drafted': True, 'blog_cover_ready': True}
eff={'blog_live': True}
cost=1.0 resources=(none)
write_linkedin_post pre={'outline_ready': True}
eff={'linkedin_drafted': True}
cost=2.0 resources={'writer_hours': 1.0, 'cost_usd': 10.0, 'quality_score': 4.0}
generate_linkedin_image pre={'linkedin_drafted': True}
eff={'linkedin_image_ready': True}
cost=1.0 resources={'gpu_minutes': 2.0, 'cost_usd': 5.0}
publish_linkedin pre={'linkedin_drafted': True, 'linkedin_image_ready': True}
eff={'linkedin_live': True}
cost=1.0 resources=(none)
write_twitter_thread pre={'outline_ready': True}
eff={'twitter_drafted': True}
cost=1.0 resources={'writer_hours': 0.5, 'cost_usd': 4.0, 'quality_score': 2.0}
generate_twitter_image pre={'twitter_drafted': True}
eff={'twitter_image_ready': True}
cost=1.0 resources={'gpu_minutes': 1.0, 'cost_usd': 2.0}
publish_twitter pre={'twitter_drafted': True, 'twitter_image_ready': True}
eff={'twitter_live': True}
cost=1.0 resources=(none)
GOAP Execution Graph#
The planner discovers a plan, the executor runs each action, and the observer checks progress — replanning automatically if something fails.
from IPython.display import Image, display
from langgoap import GoapGraph
graph = GoapGraph(actions=actions)
display(Image(graph.compile().get_graph().draw_mermaid_png()))
Note the two blog writers. Both have the same precondition (outline_ready=True) and the same effect (blog_drafted=True), but their profiles are very different:
Writer |
cost |
writer_hours |
cost_usd |
quality_score |
|---|---|---|---|---|
|
3.0 |
2.0 |
30.0 |
5.0 |
|
6.0 |
6.0 |
80.0 |
10.0 |
Because A* optimizes pure action cost, it will always prefer the fast writer in the primary plan. Section 3 forces the deep writer through a hard quality constraint and the CSP enumeration path.
2. Unconstrained blog-only plan — pure A*#
With no constraints or objectives the pipeline is a pass-through: needs_csp(goal) returns False and pipeline_plan() forwards straight to astar_plan(). The resulting Plan has a SimpleScore equal to total_cost and no metadata.csp attached.
from langgoap.planner.pipeline import plan as pipeline_plan
start = content_builder_start()
plan = pipeline_plan(start, blog_only_goal(), actions)
assert plan is not None
print("plan actions :", list(plan.action_names))
print("total_cost :", plan.total_cost)
print("score type :", type(plan.score).__name__)
print("score value :", plan.score.value)
print("metadata.csp :", plan.metadata.csp)
display(Image(plan.draw_mermaid_png()))
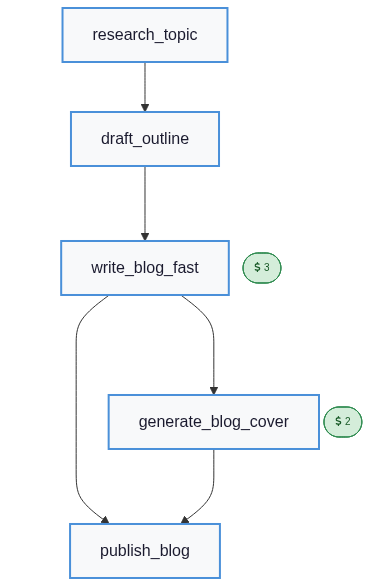
Five actions, total cost 8.0, SimpleScore(8.0), no CSP metadata — exactly what the integration test TestBlogOnlyPlan::test_pipeline_skips_csp_for_unconstrained_blog_goal pins.
3. Conditional format generation via CSP enumeration#
Adding a hard quality_score >= 8 constraint changes the story. The primary A* plan still uses write_blog_fast (quality total = 5), so validate_plan() marks it INFEASIBLE. The pipeline then enters enumerate_alternatives():
Blacklist each action in the rejected plan one at a time.
Re-run A* with the trial blacklist.
Collect every distinct alternative plan.
The blacklist on write_blog_fast produces the deep-writer alternative with quality total = 10, and optimize_plans() selects it. The final plan the pipeline returns is the deep plan — with a HardSoftScore showing hard=0.0 and a positive soft contribution from the MAXIMIZE objective.
quality_goal = quality_blog_goal(min_quality=8.0)
plan = pipeline_plan(start, quality_goal, actions)
assert plan is not None
print("final plan :", list(plan.action_names))
print("total_cost :", plan.total_cost)
print("score type :", type(plan.score).__name__)
print("hard :", plan.score.hard)
print("soft :", plan.score.soft)
print("is_feasible :", plan.score.is_feasible())
meta = plan.metadata.csp
assert meta is not None
print(f"\ncsp status : {meta.status.value}")
print(f"plans evaluated : {meta.plans_evaluated}")
print("\nresource usage after enumeration:")
for u in meta.resource_usage:
bound = (
f"min={u.constraint_min}" if u.constraint_min is not None else f"max={u.constraint_max}"
)
print(f" {u.key:<16s} total={u.total} {bound} satisfied={u.satisfied} level={u.level}")
final plan : ['research_topic', 'draft_outline', 'write_blog_deep', 'generate_blog_cover', 'publish_blog']
total_cost : 11.0
score type : HardSoftScore
hard : 0.0
soft : 10.0
is_feasible : True
csp status : optimal
plans evaluated : 1
resource usage after enumeration:
cost_usd total=110.0 max=None satisfied=True level=info
gpu_minutes total=5.0 max=None satisfied=True level=info
quality_score total=10.0 min=8.0 satisfied=True level=hard
writer_hours total=9.0 max=None satisfied=True level=info
display(Image(plan.draw_mermaid_png()))
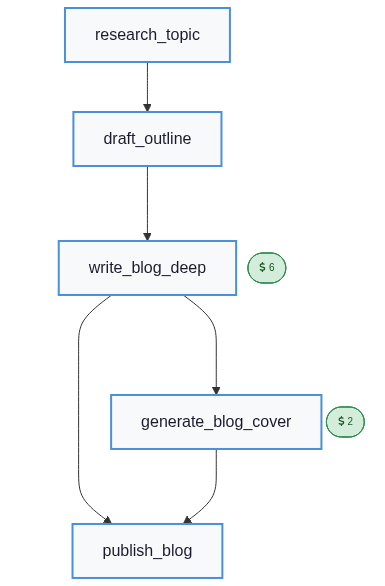
The plan is now the deep-writer chain, and the quality_score resource clears the 8.0 floor with room to spare (10.0 total). The HardSoftScore shows hard=0.0 (feasible) and soft=10.0 because the MAXIMIZE quality_score objective adds the aggregated quality to the soft score.
Lowering the floor to 5 (the exact quality of the fast writer) is enough to pass validation without enumeration — the primary plan is returned as-is:
relaxed_goal = quality_blog_goal(min_quality=5.0)
relaxed = pipeline_plan(start, relaxed_goal, actions)
assert relaxed is not None
print("relaxed plan :", list(relaxed.action_names))
print("writer used :", "fast" if "write_blog_fast" in relaxed.action_names else "deep")
assert relaxed.metadata.csp is not None
print("csp status :", relaxed.metadata.csp.status.value)
relaxed plan : ['research_topic', 'draft_outline', 'write_blog_fast', 'generate_blog_cover', 'publish_blog']
writer used : fast
csp status : feasible
4. Fluent ConstraintBuilder — the constraint-provider analogue#
Hand-rolling GoalSpec(constraints=(ConstraintSpec(...),), objectives={...}) gets verbose fast. ConstraintBuilder offers a readable, chainable alternative following the penalize/reward convention used in constraint-provider DSLs. Every goal factory in content_builder_agent.py has a twin built via the fluent API, and both forms produce structurally identical GoalSpec instances.
The quality goal in fluent form is:
from langgoap.constraints import ConstraintBuilder
from langgoap import GoalSpec
output = ConstraintBuilder.build(
ConstraintBuilder.for_plan()
.sum_resource("quality_score")
.bounded(min=8.0)
.penalize(level="hard", weight=1.0)
.as_constraint("quality_score"),
ConstraintBuilder.for_plan()
.sum_resource("quality_score")
.maximize()
.as_objective("quality_score"),
)
fluent_goal = GoalSpec.from_builder(
conditions={"blog_live": True},
builder_output=output,
)
print("constraints :")
for c in fluent_goal.constraints:
print(f" key={c.key!r} min={c.min} max={c.max} level={c.level!r} weight={c.weight}")
print(f"objectives : {dict(fluent_goal.objectives or {})}")
constraints :
key='quality_score' min=8.0 max=None level='hard' weight=1.0
objectives : {'quality_score': <ObjectiveDirection.MAXIMIZE: 'maximize'>}
Running the pipeline against the fluent-built goal produces the same deep-writer plan as the hand-rolled form:
hand_plan = pipeline_plan(start, quality_blog_goal(min_quality=8.0), actions)
fluent_plan = pipeline_plan(start, quality_blog_goal_fluent(min_quality=8.0), actions)
assert hand_plan is not None and fluent_plan is not None
print("same action list:", list(hand_plan.action_names) == list(fluent_plan.action_names))
print("same total_cost :", hand_plan.total_cost == fluent_plan.total_cost)
print("same score :", hand_plan.score == fluent_plan.score)
same action list: True
same total_cost : True
same score : True
6. A too-tight hard cap — unreachable, not just expensive#
The enumeration path in section 3 worked because there was an alternative plan — the deep writer produced the same effect via a different action. What happens when a hard constraint is so tight that no subset of actions can satisfy the goal?
Setting max_cost_usd=50 on the multi-channel goal is exactly that situation. The fast plan costs 81.0 so validation rejects it. Every action in the rejected plan is load-bearing — blacklisting write_linkedin_post (or publish_blog, or any other) removes the only path to one of the required effects, so A* returns nothing under every trial blacklist. Enumeration yields zero alternatives and the pipeline returns the primary plan with INFEASIBLE metadata. The caller is expected to inspect plan.metadata.csp.status and decide whether to proceed, relax the cap, or abort.
infeasible_goal = multi_channel_goal(max_cost_usd=50.0, max_cost_level="hard")
infeasible_plan = pipeline_plan(start, infeasible_goal, actions)
assert infeasible_plan is not None
meta = infeasible_plan.metadata.csp
assert meta is not None
print(f"csp status : {meta.status.value}")
print(f"hard : {infeasible_plan.score.hard}")
print(f"is_feasible : {infeasible_plan.score.is_feasible()}")
cost_usage = next(u for u in meta.resource_usage if u.key == "cost_usd")
print(
f"cost_usd : total={cost_usage.total} max={cost_usage.constraint_max} violated={not cost_usage.satisfied}"
)
All alternative plans infeasible
csp status : infeasible
hard : -31.0
is_feasible : False
cost_usd : total=81.0 max=50.0 violated=True
Swapping the same cap to level="soft" is enough to keep the plan feasible with an explicit soft penalty, so downstream consumers can still execute it and accept the over-budget trade-off:
softcap_goal = multi_channel_goal(max_cost_usd=50.0, max_cost_level="soft")
softcap_plan = pipeline_plan(start, softcap_goal, actions)
assert softcap_plan is not None
meta = softcap_plan.metadata.csp
assert meta is not None
print(f"csp status : {meta.status.value}")
print(f"hard : {softcap_plan.score.hard}")
print(f"soft : {softcap_plan.score.soft}")
print(f"is_feasible : {softcap_plan.score.is_feasible()}")
csp status : feasible
hard : 0.0
soft : -112.0
is_feasible : True
7. End-to-end execution via GoapGraph#
Every plan in this notebook is returned by the pipeline in isolation, but the same goals flow through GoapGraph.invoke() unchanged — the graph runs the planner, executes each action, and loops back through the observer until the goal is satisfied. Here’s the quality-constrained goal end-to-end:
from langgoap import GoapGraph
graph = GoapGraph(content_builder_actions(llm))
result = graph.invoke(
goal=quality_blog_goal(min_quality=8.0),
world_state={**content_builder_start(), "topic": "AI agent planning"},
)
print(f"status : {result['status']}")
print("\nexecution history (deep writer selected by CSP enumeration):")
for i, record in enumerate(result["execution_history"]):
print(f" step {i + 1} {record.action_name}")
# Show LLM-generated content
ws = result["world_state"]
print(f"\nresearch findings (first 200 chars):\n {ws.get('research_findings', '')[:200]}...")
print(f"\nblog content (first 300 chars):\n {ws.get('blog_content', '')[:300]}...")
status : goal_achieved
execution history (deep writer selected by CSP enumeration):
step 1 research_topic
step 2 draft_outline
step 3 write_blog_deep
step 4 generate_blog_cover
step 5 publish_blog
research findings (first 200 chars):
- AI agent planning involves the use of algorithms and models to enable autonomous agents to make decisions and execute tasks effectively. A common approach is the use of Markov Decision Processes (MD...
blog content (first 300 chars):
# The Future of Decision-Making: Unpacking AI Agent Planning
In an era where technology is rapidly evolving, the concept of AI agent planning has emerged as a cornerstone of autonomous decision-making. This sophisticated approach enables machines to make informed decisions and execute tasks with mi...
Summary#
A alone finds the cheapest plan*; adding constraints or objectives routes the goal through CSP.
Hard constraint violations trigger
enumerate_alternatives(). The pipeline blacklists each action in the rejected plan one at a time and re-runs A*. If an alternative clears the hard floor,optimize_plans()selects it.Soft constraint violations do not change the plan — they record a penalty in
HardSoftScore.softso callers can see the trade-off.ConstraintBuilderis a fluent constraint-provider analogue. Every constraint and objective in this notebook was built via the fluent API and produces the sameGoalSpecas the hand-rolled form.GoalSpec.from_builder(conditions, builder_output)is the one-line bridge.HardSoftScoredecomposes into hard, soft, and per-objective contributions that the integration test pins exactly. No>=weakened assertions.The GOAP pipeline is advisory for infeasibility. When no alternative clears a hard cap, the pipeline returns the primary plan with
INFEASIBLEmetadata; the caller decides whether to proceed, relax the cap, or abort.
Next steps: combine the content builder with MultiGoal sequential mode (notebook 12) to stage a multi-day campaign where discovery, drafting, and launch are separate sub-goals, or pair it with the CSP temporal scheduler (notebook 14) to add explicit durations and critical-path Gantt visualization.