Nurse Rostering — the Standard NRP, Compacted#
A Tier 2 tutorial that translates the standard nurse rostering problem (NRP) into a LangGOAP A* + CSP pipeline with natural-language intake.
The problem#
Every shift in the schedule must be covered by exactly one qualified nurse, no nurse may work two shifts in the same day, and the total dissatisfaction — a per-(nurse, shift) preference cost — should be minimized.
This tutorial collapses the full 10-nurse / 1-week
sprint01_1week.xml benchmark instance to 1 day / 3 shifts / 4 nurses so
everything solves instantly while still exercising the features
that matter:
Skill matching —
morningrequirestriage,afternoonrequiresgeneral,nightrequirespediatrics. Unqualified nurses have no action to take a shift.Preference optimization — A* minimizes total unhappiness using the per-(nurse, shift) cost table as the action cost.
Soft vs hard constraints — a cap on total unhappiness can be declared
hard(INFEASIBLE on violation) orsoft(a weighted penalty on theHardSoftScore).Natural-language intake — a
GoalInterpreterturns phrases like “ideally keep everybody happy” into the same GoalSpec.
LangGOAP modelling#
GOAP concept |
Nurse rostering interpretation |
|---|---|
|
|
precondition |
|
effect |
|
|
|
|
|
goal |
every shift covered |
goal |
minimize |
goal |
hard/soft cap on total |
Encoding unhappiness as both the action cost and a unhappiness
resource lets A* pick the happiest plan directly while still giving
CP-SAT a scalar to minimize, penalize, or bound. The CSP phase builds
a HardSoftScore from the unhappiness -> MINIMIZE objective plus any
constraint penalties — a fluent constraint-provider pattern
expressed in native Python.
import logging
# The hard-infeasibility demo further down deliberately triggers the
# CSP's "all alternatives infeasible" advisory — silence the warning.
logging.getLogger("langgoap").setLevel(logging.ERROR)
from tutorial_examples.data.nurse_rostering_instance import (
NURSES,
PREFERENCE_COST,
SHIFTS,
)
from tutorial_examples.nurse_rostering import (
nurse_rostering_actions,
nurse_rostering_goal,
nurse_rostering_start,
)
from langgoap import CSPStatus, GoapGraph
from langgoap.planner.pipeline import plan as pipeline_plan
print("Shifts:")
for s in SHIFTS:
print(f" {s.name:10s} requires {s.required_skill:11s} hours={s.hours}")
print("\nNurses:")
for n in NURSES:
print(f" {n.name:6s} skills={sorted(n.skills)}")
1. The preference matrix#
Each (nurse, shift) cell is the unhappiness cost of that
assignment. Blank cells mean the nurse lacks the required skill —
the action catalog will not even include those pairs. Lower is
happier; a zero means the nurse actively prefers that shift.
header = f"{'nurse':<8}" + "".join(f"{s.name:>12s}" for s in SHIFTS)
print(header)
print("-" * len(header))
for nurse in NURSES:
row = f"{nurse.name:<8}"
for shift in SHIFTS:
if shift.required_skill in nurse.skills:
cost = PREFERENCE_COST[(nurse.name, shift.name)]
row += f"{cost:>12d}"
else:
row += f"{'—':>12s}"
print(row)
nurse morning afternoon night
--------------------------------------------
alice 4 0 7
bob — 3 6
carol 1 5 —
dave — 4 0
2. Action catalog — skill filter at build time#
nurse_rostering_actions() builds one ActionSpec per qualified
(nurse, shift) pair. Bob, Carol and Dave cannot take the morning
triage shift, so those actions are absent from the catalog entirely
— the planner never considers illegal placements.
actions = nurse_rostering_actions()
print(f"Total legal actions: {len(actions)}\n")
for a in actions:
print(f" {a.name:34s} cost={a.cost:<3.0f} resources={dict(a.resources)}")
Total legal actions: 9
assign_alice_to_morning cost=4 resources={'unhappiness': 4.0}
assign_alice_to_afternoon cost=0 resources={'unhappiness': 0.0}
assign_alice_to_night cost=7 resources={'unhappiness': 7.0}
assign_bob_to_afternoon cost=3 resources={'unhappiness': 3.0}
assign_bob_to_night cost=6 resources={'unhappiness': 6.0}
assign_carol_to_morning cost=1 resources={'unhappiness': 1.0}
assign_carol_to_afternoon cost=5 resources={'unhappiness': 5.0}
assign_dave_to_afternoon cost=4 resources={'unhappiness': 4.0}
assign_dave_to_night cost=0 resources={'unhappiness': 0.0}
GOAP Execution Graph#
The planner discovers a plan, the executor runs each action, and the observer checks progress — replanning automatically if something fails.
from IPython.display import Image, display
graph = GoapGraph(actions=actions)
display(Image(graph.compile().get_graph().draw_mermaid_png()))
3. Solve the happiest roster#
The default goal asks for every shift to be covered and adds an
unhappiness → MINIMIZE objective so the plan routes through the
CSP phase and receives a HardSoftScore.
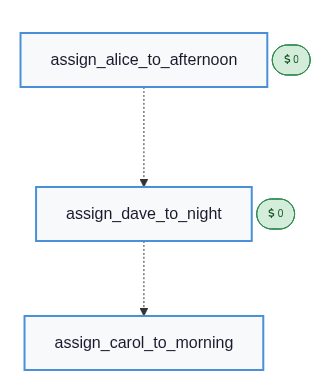
A* finds the minimum-cost plan using action costs as the g-values. The optimal assignment is alice → afternoon (0) + dave → night (0) + carol → morning (1) = 1; every other legal assignment scores strictly higher.
plan_obj = pipeline_plan(
nurse_rostering_start(),
nurse_rostering_goal(),
actions,
)
print(f"CSP status: {plan_obj.metadata.csp.status.value}")
print(f"Total unhappiness: {plan_obj.total_cost:.0f}\n")
print("Roster:")
for step in plan_obj.actions:
# step.name format: "assign_<nurse>_to_<shift>"
nurse, shift = step.name.removeprefix("assign_").split("_to_")
cost = int(step.cost)
print(f" {shift:10s} ← {nurse:6s} (cost {cost})")
display(Image(plan_obj.draw_mermaid_png()))
4. HardSoftScore decomposition#
When a goal has constraints or objectives the pipeline replaces
the pure-A* SimpleScore with a HardSoftScore derived from the
CSP metadata:
hardis0for every feasible plan; hard-constraint violations subtract the (weighted) amount of each overshoot.softaggregates objective contributions (minus forMINIMIZE, plus forMAXIMIZE) and weighted soft-constraint violations.
With no constraints declared, soft is simply -unhappiness.
print(f"plan.score = {plan_obj.score}")
print(f"score.is_feasible = {plan_obj.score.is_feasible()}")
print(f"score.value = {plan_obj.score.value} (scalar for logging)")
print(f"\nObjective values: {plan_obj.metadata.csp.objective_values}")
for u in plan_obj.metadata.csp.resource_usage:
print(f" {u.key:12s} total={u.total:<5.1f} level={u.level}")
plan.score = HardSoftScore(hard=0, soft=-1)
score.is_feasible = True
score.value = -1.0 (scalar for logging)
Objective values: {'unhappiness': 1.0}
unhappiness total=1.0 level=info
5. Soft constraints — penalty, not rejection#
Adding a soft cap on unhappiness lets the pipeline report a
penalty on the HardSoftScore while still returning a feasible
plan. The same cap at level="hard" would flip the status to
INFEASIBLE (see the next section).
Here we set max_unhappiness=0.0 — the optimal plan has total
unhappiness 1, so the penalty is exactly 1. The soft component of
the score becomes -objective(1) - penalty(1) = -2.
soft_plan = pipeline_plan(
nurse_rostering_start(),
nurse_rostering_goal(max_unhappiness=0.0, max_unhappiness_level="soft"),
actions,
)
print(f"CSP status: {soft_plan.metadata.csp.status.value}")
print(f"Score: {soft_plan.score}")
usage = next(u for u in soft_plan.metadata.csp.resource_usage if u.key == "unhappiness")
print(f"\nunhappiness usage: total={usage.total} max={usage.constraint_max} "
f"satisfied={usage.satisfied} level={usage.level}")
6. Hard cap → INFEASIBLE status#
Flipping the same cap to level="hard" makes the plan infeasible:
the A* search still returns the happiest roster (total = 1), but
the CSP validator marks the status infeasible, re-runs A* with
each action blacklisted to enumerate alternatives, and reports
that none of them fit either.
plan.metadata.csp is advisory — the pipeline still returns
the primary plan, stamped with the hard = -overshoot penalty on
HardSoftScore. Callers decide whether to execute or escalate.
hard_plan = pipeline_plan(
nurse_rostering_start(),
nurse_rostering_goal(max_unhappiness=0.0, max_unhappiness_level="hard"),
actions,
)
print(f"CSP status: {hard_plan.metadata.csp.status.value}")
print(f"Score: {hard_plan.score}")
print(f"is_feasible: {hard_plan.score.is_feasible()}")
print(f"\n(Every alternative also carries total unhappiness >= 1 — CSP tried "
f"{len(actions)} blacklist variants and none fit.)")
7. Natural-language intake#
The NL interpreter turns a free-text request into the same
GoalSpec we constructed by hand above. In production you’d pass
an OpenAI, Anthropic or Google chat model; here we use a
FakeStructuredModel that returns a pre-canned InterpretedGoal
so the notebook runs offline.
Notice how the LLM extracts:
conditions — every
shift_<name>_covered=True.soft constraint — “ideally keep total unhappiness under 3” →
ConstraintSpec(key="unhappiness", max=3, level="soft").objective — “as happy as possible” →
unhappiness → MINIMIZE.
from langgoap import (
GoalInterpreter,
InterpretedConstraint,
InterpretedGoal,
InterpretedObjective,
)
from langgoap.testing import FakeStructuredModel
interpreted = InterpretedGoal(
conditions={f"shift_{s.name}_covered": True for s in SHIFTS},
constraints=[
InterpretedConstraint(key="unhappiness", max=3.0, level="soft")
],
objectives=[
InterpretedObjective(metric="unhappiness", direction="minimize")
],
reasoning=(
"Cover every shift; 'ideally keep people happy' becomes a "
"soft cap on total unhappiness plus a minimize objective."
),
)
llm = FakeStructuredModel(response=interpreted)
interpreter = GoalInterpreter(llm=llm, actions=actions)
nl_goal = interpreter.interpret(
"Please cover every shift tomorrow and keep the team as happy as "
"possible — ideally total unhappiness under 3."
)
print("Interpreted conditions:", dict(nl_goal.conditions))
print("Interpreted constraints:")
for c in nl_goal.constraints:
print(f" {c.key} max={c.max} level={c.level}")
print("Interpreted objectives:", dict(nl_goal.objectives) if nl_goal.objectives else None)
print(f"\nReasoning: {interpreted.reasoning}")
Interpreted conditions: {'shift_morning_covered': True, 'shift_afternoon_covered': True, 'shift_night_covered': True}
Interpreted constraints:
unhappiness max=3.0 level=soft
Interpreted objectives: {'unhappiness': <ObjectiveDirection.MINIMIZE: 'minimize'>}
Reasoning: Cover every shift; 'ideally keep people happy' becomes a soft cap on total unhappiness plus a minimize objective.
8. End-to-end via GoapGraph.invoke_nl()#
The one-liner invoke_nl() composes the three stages: the LLM
interprets the request, the A* + CSP pipeline finds the happiest
feasible roster, and the executor advances the world state
through the plan until every condition is satisfied.
result = GoapGraph(actions=actions).invoke_nl(
"Please cover every shift tomorrow and keep the team as happy as "
"possible — ideally total unhappiness under 3.",
llm=FakeStructuredModel(response=interpreted),
world_state=nurse_rostering_start(),
)
print(f"Status: {result['status']}")
print("\nFinal world state:")
for k, v in sorted(result["world_state"].items()):
print(f" {k:28s} = {v}")
Status: goal_achieved
Final world state:
nurse_alice_available = False
nurse_bob_available = True
nurse_carol_available = False
nurse_dave_available = False
shift_afternoon_covered = True
shift_morning_covered = True
shift_night_covered = True
Summary#
Skill matching for free. The action catalog excludes unqualified pairs at build time, so A* never considers illegal placements.
Preferences become action costs. A* minimizes total unhappiness directly using the preference matrix; the CSP layer attaches the
HardSoftScorewithout re-searching.Soft vs hard is one keyword. The same cap swings between penalty on the score and INFEASIBLE plan status.
NL intake is a drop-in upgrade.
GoalInterpreter-> the identical pipeline; swapFakeStructuredModelfor anyBaseChatModelto go live.
Every scenario above is verified by
tests/integration/test_nurse_rostering.py.
What’s out of scope for this tutorial#
The full sprint01_1week.xml benchmark instance adds multi-day
patterns, consecutive-work-day limits, unwanted-shift patterns and
contract-level min/max assignment counts. LangGOAP’s flat world
state can approximate these via per-nurse counters, but encoding
them here would drown out the point — skill matching, preference
optimization, and the hard/soft score pipeline. See the data
module docstring for the full provenance trail.